
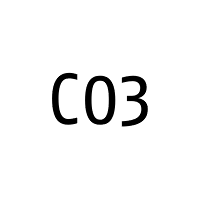
![[Open Data]](https://assets.okfn.org/images/ok_buttons/od_80x15_blue.png)
Corpus consisting of English utopias ranging from the 15th century till the present. The corpus consists of input and output files. Input files are the utopias in book form. Output files are the OCR and natural language processing (NLP) results. NLP processes include among others part of speech tagging (POS) and semantic tagging using the UCREL Semantic Analysis System (USAS).
Data and Resources
- Adam Sternbergh - 2014 - Shovel Readypdf
This version of shovel Ready written by Adam Sternbergh was published in...
Download